

Welcome to the world of Web Scraping with Python! In this beginner’s guide, you will learn the art of extracting valuable information from websites.
The internet is full of valuable information, still, many people and businesses struggle with getting all the information they need.
For example, people may want to keep track of the price of a specific product. However, there are just too many different shopping sites with different prices to keep track of.
That’s where you come into play! With the skills you’ll learn in this guide, you will be able to collect all the information from all the websites and either use them yourself or provide them to other people in one single place.
Keep reading to find out more!
#1 What is Web Scraping
Web scraping refers to the process of gathering information from the World Wide Web.
In theory, even copying and pasting code from Stack Overflow can be considered an act of gathering information, thus classifying it as a form of web scraping.
However, that’s not what is usually meant when talking about Web Scraping.
Typically, this process is automated using a program that searches for specific pieces of information.
Why Scrape the Web?
Suppose you’re an SEO (Search Engine Optimization) specialist aiming to improve your website’s visibility in search results. Instead of manually brainstorming and guessing keywords, you can make use of web scraping to automatically obtain valuable data from search engine results.
For example, you can create a scraper that navigates search engines, retrieves top-ranking keywords, and analyzes their popularity and competition.
With this data-driven approach, you can identify great keywords with optimal search volumes and lower competition, enabling you to write good content and attract more organic traffic. By consistently monitoring changes in keyword trends through periodic web scraping, you can adapt your SEO strategy and stay ahead of the competition.
That’s only one example of many use cases for web scraping.
In fact, businesses are willing to pay a lot of money for a service that provides them with such important and well-structured data so that they don’t have to hire employees to collect all the data manually.
And even for your own projects, automated web scraping can be a huge time saver!
The Challenges of Scraping the Web
While web scraping opens up a wealth of data possibilities, it also presents a couple of challenges.
Most websites are constantly undergoing redesigns, internal changes, or other updates, leading to shifts in the HTML layout.
What might work at the time of writing your web scraper might not work anymore the next week.
Also, many sites don’t want to be scraped. Therefore, they implement anti-scraping mechanisms like CAPTCHAS, IP blocking, or rate limiting.
Even if they don’t have such mechanisms in place, they can forbid automated data collection in their Terms & Conditions. Still scraping them would then be illegal.
Another problem is the variety of websites. If you want to gather data from more than one website, your scraper must be able to adapt to a completely different website.
The more websites you are planning to scrape, the harder it gets to code a functioning web scraper.
Despite these challenges, understanding and mitigating them with respect for the website owners’ rights can lead to successful and responsible web scraping, providing valuable data for various legitimate use cases.
Why use Python for Web Scraping?
Python has emerged as the leading choice for web scraping, gaining popularity among developers and data enthusiasts alike. Its versatility, simplicity, and a big ecosystem of powerful libraries make it an ideal language for this task. Here are some reasons why Python is the preferred language for web scraping:
- Ease of Learning and Use: Python’s intuitive syntax allows beginners to quickly grasp the language fundamentals. Its readability makes writing and maintaining a web-scraping script relatively easy, even for those with limited programming experience.
- Abundance of Libraries: Python offers a ton of libraries specifically for web scraping. Beautiful Soup and Requests simplify HTML parsing and data retrieval, while Selenium handles dynamic content with ease.
- Cross-Platform Capability: Python code can run on almost any operating system. Hence, scraping scripts can be run seamlessly on various devices.
- Community and Support: Python’s large and active community ensures continuous support and a lot of resources. From tutorials and documentations to ready-made scripts and code snippets, Python’s strong community has got it all.
#2 How Web Scraping with Python is Done
Setting up Python and Pip
Before we get started with writing code, we need to install Python with its package manager Pip.
If you have already got Python installed on your computer, feel free to skip this step!
Let’s start with the installation process for Windows.
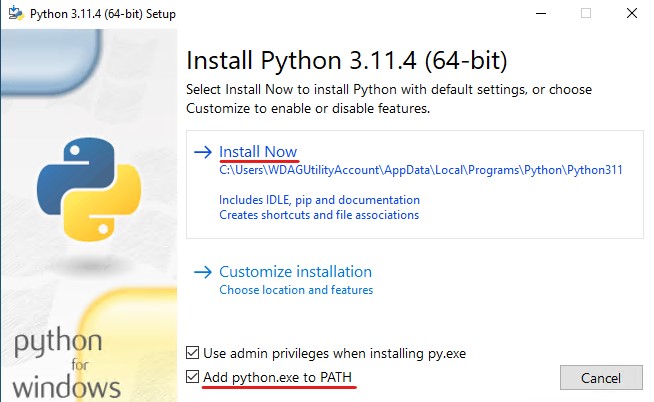
Luckily, the installation process is straightforward. Simply head to Python.org and download the latest release. After downloading, run the installer and follow the instructions there. Just make sure to tick “Add python.exe to PATH” and hit Install Now.
If you’re on Linux, simply run the following command in your terminal:
sudo apt install python3-pip
After Python is done installing, create a file with the extension .py in your project folder. py-Files are where you save your Python code.
You can run the code with a simple command in your terminal:
// On Windows
python <filename>.py
// On Mac and Linux
python3 <filename>.py
Make sure you have navigated to the path where your python file is stored. Otherwise python can’t find the file you’re trying to execute.
You can change the path in your terminal using the cd command
(e. g. cd “C:\Projects\WebScraping”)
Requesting the Website's Source Code
In order to retrieve our data, we need to access a website and get its source code. Specifically its HTML code, because that’s where the information that is displayed on a website is stored.
To do so, we make use of a popular Python library called Requests.
It can be installed with a single Pip command in your terminal:
pip install requests
The requests library provides a lot of useful methods. However, we’re only going to make use of the get() method in this beginner’s guide.
It allows us to send an HTTP GET request to a server to get a website’s HTML code.
Recommended: How to send Get & Post Requests in Python
Let’s take example.com as a simple example:
import requests # import the requests library into our python program
response = requests.get('http://example.com') # get the html code
print(response.text) # print the received code
After running this code snippet, you’ll see that the program has retrieved the HTML code of example.com and printed it in your terminal.
The next step is to exctract only the data we actually want.
Gathering the Data with Beautiful Soup
Once we’ve acquired a website’s HTML code using the Requests library, the next step in our web scraping journey is to extract meaningful data from it. This is where Beautiful Soup comes into play – a Python library, allowing us to browse HTML structure and exctract valuable information from it.
Again, we can install Beautiful Soup 4 with a single Pip command in your terminal:
pip install beautifulsoup4
After installing, let’s start with a simple example again.
Therefore, we’re going to enhance our previous code, where we tested the Requests library:
import requests # import requests
from bs4 import BeautifulSoup # import Beautiful Soup
# Get the HTML code
response = requests.get('http://example.com')
# Parse the code to Beautiful Soup
soup = BeautifulSoup(response.text, 'html.parser')
# Print the title tag of the website
print(soup.title)
This example, will get the HTML code of example.com using requests and print the title tag using BeautifulSoup as follows:
Of course, you can also search different elements by their attributes.
That’s done using find, find_all, or select:
# Return the first matching result
soup.find('p', class_='test') # find first paragraph tag with class "test"
# Return all matching results (can return an empty list)
soup.find_all('p', class_='test') # find all paragraphs with class "test
# Note the underscore after class (No underscore for id)
# Find elements by CSS selector (can return an empty list)
soup.select('a.test') # Returns a list of all matching elements
Of course, these are only the basic functions of BeautifulSoup, and there are a lot more to discover.
If you start your first web scraping project, you’ll get in touch with them by looking things up in documentations or forums.
Interacting with Websites using Selenium
While Beautiful Soup is great for parsing static HTML content, some websites integrate dynamic elements that require a more interactive approach. This is where Selenium comes in handy – a popular Python library designed for web automation and dynamic content interaction.
We start by installing Selenium with a Pip command in your terminal:
pip install selenium
Fortunately, in the latest versions of Selenium, there’s no longer a need for a manual installation of a browser’s web driver.
Let’s start with a simple example again. We will be trying to access coolplaydev.com and reject the cookies:
from selenium import webdriver
from selenium.webdriver.common.by import By # to search elements by different attributes
import time # to let the program wait at the end
driver = webdriver.Chrome() # Inizialize the webdriver
driver.get('https://coolplaydev.com') # Open the website
driver.implicitly_wait(2) # Wait for the website to load
# Click the "View preferences" button on the cookie banner
view_preferences_button = driver.find_element(By.CLASS_NAME, 'cmplz-view-preferences')
view_preferences_button.click()
driver.implicitly_wait(2) # If necessary, wait again
# Click the "Save preferences" button
save_preferences_button = driver.find_element(By.CLASS_NAME, 'cmplz-save-preferences')
save_preferences_button.click()
time.sleep(5) # keep the program running for 5 seconds to see the result
# Close the the web driver and the browser window
driver.close()
This code snippet will open coolplaydev.com in an automated browser window and search for the view preferences and save preferences button by their class names to reject the optional cookies.
Let’s analyze a bit further what some of these lines do:
driver = webdriver.Chrome()
Here, we initialize our web driver. This will open a new browser window of our choice. In this example, we used Chrome. However, you can also use some other popular browsers.
driver.implicitly_wait(2)
The implicitly_wait method is similar to a timeout. Basically it tells the web driver to wait until the website is loaded and responsive. The argument (In this case 2) defines how long the driver is going to wait before throwing an error. Therefore, the program does not explicitly wait 2 seconds and can proceed earlier as soon the website’s loaded.
view_preferences_button = driver.find_element(By.CLASS_NAME, 'cmplz-view-preferences')
view_preferences_button.click()
In the first line, we try to find an element of class “cmplz-view-preferences”
Remember that we imported By from selenium.webdriver.common.by in the beginning to be able to search elements by different attributes (e. g. by class name)
In the second line, we simply simulate a mouse click on the element if it’s clickable.
Handling Common Web Scraping Challenges
- Changing website structures: To tackle the challenge of constantly shifting HTML structure, consider using scraping methods that target elements based on attributes rather than fixed positions. Also, regularly inspect the sites you are scraping to check for changes that might affect your scraper.
- Anti-Scraping mechanisms: Websites implement CAPTCHAs, IP blocks, and rate limiting to prevent automated scraping. To circumvent these mechanisms, try using different scraping agents with proxy servers and random delays between actions. If you want an all-in-one solution, you can also go for services like the scraping browser from BrightData.
- Website variety: To handle multiple different websites, each with a different structure, make sure to implement robust error handling in your scraper. Additionally, design your scraper in a modular way, separating data extraction logic from the rest of the script. This way, it is easier to adapt the scraper for multiple websites.
#3 Keep Practicing

As with any skill, web scraping becomes more refined with practice. While this guide equips you with fundamental knowledge, continuous practice is essential for mastering the art of web scraping. Here are some tips on how to further enhance your skills and become a professional web scraper:
- Explore diverse websites: To challenge yourself, try scraping a variety of different websites. Because each website presents unique structures and challenges, you will learn many different techniques to deal with certain problems.
- Experiment with libraries: Requests, BeautifulSoup, and Selenium offer a ton of features. Try exploring them by reading other guides and documentations. Also, play around with other libraries.
- Troubleshoot and debug: As you practice, you’ll encounter errors and unexpected behavoir. Embrace these moments as opportunities to learn! Debugging and problem solving are skills any programmer needs.
- Contribute in communites: Engage with other web scrapers by sharing your experiences and learning from others. For example, set up a GitHub profile where you share some of your work.
Conclusion
Data is the most valuable currency in our modern and digital world.
With web scraping, you have the ability to extract a ton of data from the internet and either use it for your own projects or provide it to other people and businesses in one single and structured place.
In this guide, you have learned the fundamentals of web scraping to start your journey as a web scraper.
As you proceed with this journey, keep practicing, experimenting, and refining your skills. With every website scraped, you’ll enhance your skillset and develop an intuition for effective data retrieval.
Thanks for reading and happy coding!